[Python] 한국어 형태소 분석기 체험 및 비교(Okt, Mecab, Komoran, Kkma)
한국어는 영어처럼 띄어쓰기만으로 단어를 분리하면 제대로 되질 않습니다. 한국어는 어미와 조사 등이 발달되어 있기 때문이죠! 이 대신, 한국어는 형태소에 따라 단어 분리를 하게 되는데요. 자주 쓰이는 파이썬 한국어 형태소 분석 패키지로는 바로 KoNLPy가 있습니다. 이 안에는 여러 종류의 한국어 형태소 분석기가 있는데, 저는 그 중 Okt, Komoran, Kkma, Mecab을 체험 및 비교해보았습니다!
일단 저는 구글 코랩을 이용했습니다. Okt, Komoran, Kkma는 konlpy를 설치하기만 하면 문제가 없고, mecab은 감사하게도 이곳의 도움을 받아 설치했습니다!
#install okt, komoran kkma
!pip install konlpy
#install mecab
! git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git
cd Mecab-ko-for-Google-Colab #move to Mecab-ko~ folder
!bash install_mecab-ko_on_colab190912.sh
from konlpy.tag import Kkma, Komoran, Okt, Mecab
mec = Mecab()
okt = Okt()
kkm = Kkma()
kom = Komoran()
각 케이스에 따른 형태소 분석 결과
맞춤법이 잘 지켜지고, 띄어쓰기가 잘 되어 있는 문장은 네 형태소 분석기 모두 제대로 분석하는 모습을 보입니다. 하지만, 실제 영화 리뷰나 댓글을 보면 띄어쓰기도 잘 되고 맞춤법도 잘 지켜지는 경우가 사실 대부분이라고는 할 수 없는데요. 그렇지 않은 경우에는 형태소 분석기가 어떻게 단어를 분리하는지 궁금해졌습니다. 아래는 각 경우에 해당하는 형태소 분석 결과입니다!
(1) 맞춤법은 잘 지켜졌으나 띄어쓰기가 안 된 경우
먼저, 맞춤법은 잘 지켜졌으나, 띄어쓰기가 하나도 안 되어 있는 경우입니다. 아래 문장은 그 유명한 네이버 영화 리뷰 데이터에 있는 한 문장인데요.
사랑하고싶게하는가슴속온감정을헤집어놓는영화예요정말최고
이 문장에 대해 각 형태소 분석기는 아래와 같이 분석했습니다. 형태소 맞춤법이 잘 지켜져있다면, 띄어쓰기가 안 되어 있어도 대체로 잘 지켜지는 모습을 보입니다. 띄어쓰기가 안 되어 있어도 오타가 없다면 형태소 분석 결과를 걱정할 필요는 없는 것 같습니다!
txt = '사랑하고싶게하는가슴속온감정을헤집어놓는영화예요정말최고'
mec.pos(txt, flatten=False, join=True) #mecab
kom.pos(txt,flatten=False, join=True) #komoran
kkm.pos(txt,flatten=False, join=True) #kkma
okt.pos(txt,norm=True, stem=True, join=True) #okt
-
Mecab: [[‘사랑/NNG’, ‘하/XSV’, ‘고/EC’, ‘싶/VX’, ‘게/EC’, ‘하/VV’, ‘는/ETM’, ‘가슴속/NNG’, ‘온/VV+ETM’, ‘감정/NNG’, ‘을/JKO’, ‘헤집/VV’, ‘어/EC’, ‘놓/VX’, ‘는/ETM’, ‘영화/NNG’, ‘예요/VCP+EF’, ‘정말/MAG’, ‘최고/NNG’]]
-
Komoran: [[‘사랑/NNG’, ‘하/XSV’, ‘고/EC’, ‘싶/VX’, ‘게/EC’, ‘하/VX’, ‘는/ETM’, ‘가슴속/NNG’, ‘오/VV’, ‘ㄴ/ETM’, ‘감정/NNP’, ‘을/JKO’, ‘헤집/VV’, ‘어/EC’, ‘놓/VX’, ‘는/ETM’, ‘영화/NNP’, ‘예/NNG’, ‘요정/NNP’, ‘말/NNG’, ‘최고/NNP’]]
-
Kkma: [[‘사랑/NNG’, ‘하/XSV’, ‘고/ECE’], [‘싶/VXA’, ‘게/ECD’], [‘하/VV’, ‘는/ETD’], [‘가슴속/NNG’], [‘오/VV’, ‘ㄴ/ETD’], [‘감정/NNG’, ‘을/JKO’], [‘헤집/VV’, ‘어/ECD’], [‘놓/VXV’, ‘는/ETD’], [‘영화/NNG’, ‘이/VCP’, ‘에요/EFN’], [‘정말/MAG’], [‘최고/NNG’]]
-
Okt: [‘사랑/Noun’, ‘하다/Verb’, ‘싶다/Verb’, ‘가슴속/Noun’, ‘온/Noun’, ‘감정/Noun’, ‘을/Josa’, ‘헤집다/Verb’, ‘영화/Noun’, ‘예요/Josa’, ‘정말/Noun’, ‘최고/Noun’]
분석 결과를 보았을 때, 전반적인 느낌으로는 Kkma와 Komoran은 더 구체적으로 형태소에 따라 단어를 쪼개는 것으로 보입니다. 한편, Okt의 경우 다른 분석기들과 미세하게 결과가 다른데요. Okt는 stem=True, norm=True의 파라미터가 존재해서, 단어들을 알아서 조금 정규화해주고, 오타도 조금 수정해주는 기능이 있습니다. 위와 같이, ‘사랑하고’를 ‘사랑하다’로, ‘싶게’를 ‘싶다’로, ‘헤집어놓는’을 ‘헤집다’로 바꾸었습니다. 오타를 수정해주는 것은 아래에서 확인해보겠습니다.
(2) 흔하지 않은 오타가 있고 띄어쓰기도 안 된 경우
이번에는 띄어쓰기도 안 되고, 흔하지 않은 오타도 있을 때 형태소 분석 결과가 어떤지 확인해봅시다. 아래 문장 역시 네이버 영화 리뷰 데이터에 존재하는 문장인데요.
너무재밓었다그래서보는것을추천한다
이 문장에 대해 각 형태소 분석 결과는 다음과 같습니다. 정말 모든 형태소 분석기가 급격히 혼란스러워 하고 있는 것을 확인할 수 있는데요. 이 문장에 대해서는 그래도 Kkma가 제일 안정적인 결과를 보입니다.
-
Mecab: [[‘너무/MAG’, ‘재/XPN’, ‘밓었다그래서보는것을추천한다/UNKNOWN’]]
-
Komoran: [[‘너무재밓었다그래서보는것을추천한다/NA’]]
-
Kkma: [[‘너무/MAG’], [‘재/NNG’], [‘밓/UN’], [‘어/VV’, ‘었/EPT’, ‘다/EFN’], [‘그래서/MAC’], [‘보/VV’, ‘는/ETD’], [‘것/NNB’, ‘을/JKO’], [‘추천/NNG’, ‘하/XSV’, ‘ㄴ다/EFN’]]
-
Okt: [‘너/Modifier’, ‘무재/Noun’, ‘밓었/Noun’, ‘다그/Noun’, ‘래서/Noun’, ‘보다/Verb’, ‘추천/Noun’, ‘한/Josa’, ‘다/Adverb’]
저는 이 경우를 확인한 순간, 모든 오타에 대해서 저렇게 혼란스러워하는지 궁금해졌습니다. 크롤링해서 수집한 한국어 Raw Data에 오타가 존재하지 않을 수가 없기 때문입니다. 모든 오타에 대해서 저러면 큰일인데.. 라는 생각으로 다음의 경우를 확인해보았습니다.
(3) 흔한 오타가 있고 띄어쓰기가 안 될 경우
사람들이 자주 할 만한, 그렇게 크리티컬하지는 않은 오타가 있다면 어떨까요? 아래 문장은 위의 문장에서 ‘재밓었다’를 ‘재밋었다로’ 바꾼 것입니다.
너무재밋었다그래서보는것을추천한다
이 문장에 대해 각 형태소 분석 결과는 다음과 같습니다. 위와 다르게 대체로 잘 분석하고 있는 모습을 보입니다! 심지어, Okt는 ‘재밋었다’를 ‘재밌다’로 오타 정정까지 했습니다. 다만, Komoran은 이 경우에도 혼란스러워하고 있는 것 같습니다.
-
Mecab: [[‘너무/MAG’, ‘재/XPN’, ‘밋/NNG’, ‘었/EP’, ‘다/EF’, ‘그래서/MAJ’, ‘보/VV’, ‘는/ETM’, ‘것/NNB’, ‘을/JKO’, ‘추천/NNG’, ‘한다/XSV+EC’]]
-
Komoran: [[‘너무재밋었다그래서보는것을추천한다/NA’]]
-
Kkma: [[‘너무/MAG’], [‘재/NNG’], [‘밋/UN’], [‘어/VV’, ‘었/EPT’, ‘다/EFN’], [‘그래서/MAC’], [‘보/VV’, ‘는/ETD’], [‘것/NNB’, ‘을/JKO’], [‘추천/NNG’, ‘하/XSV’, ‘ㄴ다/EFN’]]
-
Okt: [‘너무/Adverb’, ‘재밌다/Adjective’, ‘그래서/Adverb’, ‘보다/Verb’, ‘추천/Noun’, ‘한/Josa’, ‘다/Adverb’]
위 두번째 경우의 문장에서 띄어쓰기를 제대로 하고 돌려보기도 했었는데요. 그 경우에는 ‘재밓었다’만 뭉개지고 다른 단어들은 제대로 분석하고 있었습니다. 즉, 띄어쓰기도 안 되고, 크리티컬한 오타가 존재할 때, 형태소 분석이 잘못될 가능성이 매우 높아지는 것 같습니다.
소요 시간의 비교
형태소 분석기를 고를 때 알아야 할 또 다른 자질(?)은 아마 속도일 것입니다! 아무리 분석 결과가 안정적이라 해도, 형태소 분석을 하는데 미친듯이 느리다면 자주 사용하기 어려울 것입니다. 특히 형태소 분석할 문장이 정말 많을 경우에는 거의 이용할 수 없게 됩니다! 그래서 저는 네이버 영화 리뷰 데이터의 10000개 문장에 대해 각 분석기의 소요 시간을 구해보았습니다.
import time
from tqdm import tqdm
def tagger_time(tagger, texts):
time_sum = 0
for sentence in tqdm(texts):
t1 = time.time()
try:
tagger.morphs(sentence)
except:
pass
t2 = time.time()
time_sum += (t2 - t1)
return time_sum
texts = train['document'][:10000]
time_list = []
for tagger in [kkm, kom, okt, mec]:
time_list.append(tagger_time(tagger, texts))
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
tagger = ['Kkma', 'Komoran', 'Okt', 'Mecab']
plt.figure(figsize=(10,8))
plt.bar(tagger, time_list, color=(0.4,0.7,0.5))
plt.title('Learning Time for 10000 reviews', fontsize=17)
plt.xticks(fontsize=14)
plt.ylabel('total seconds')
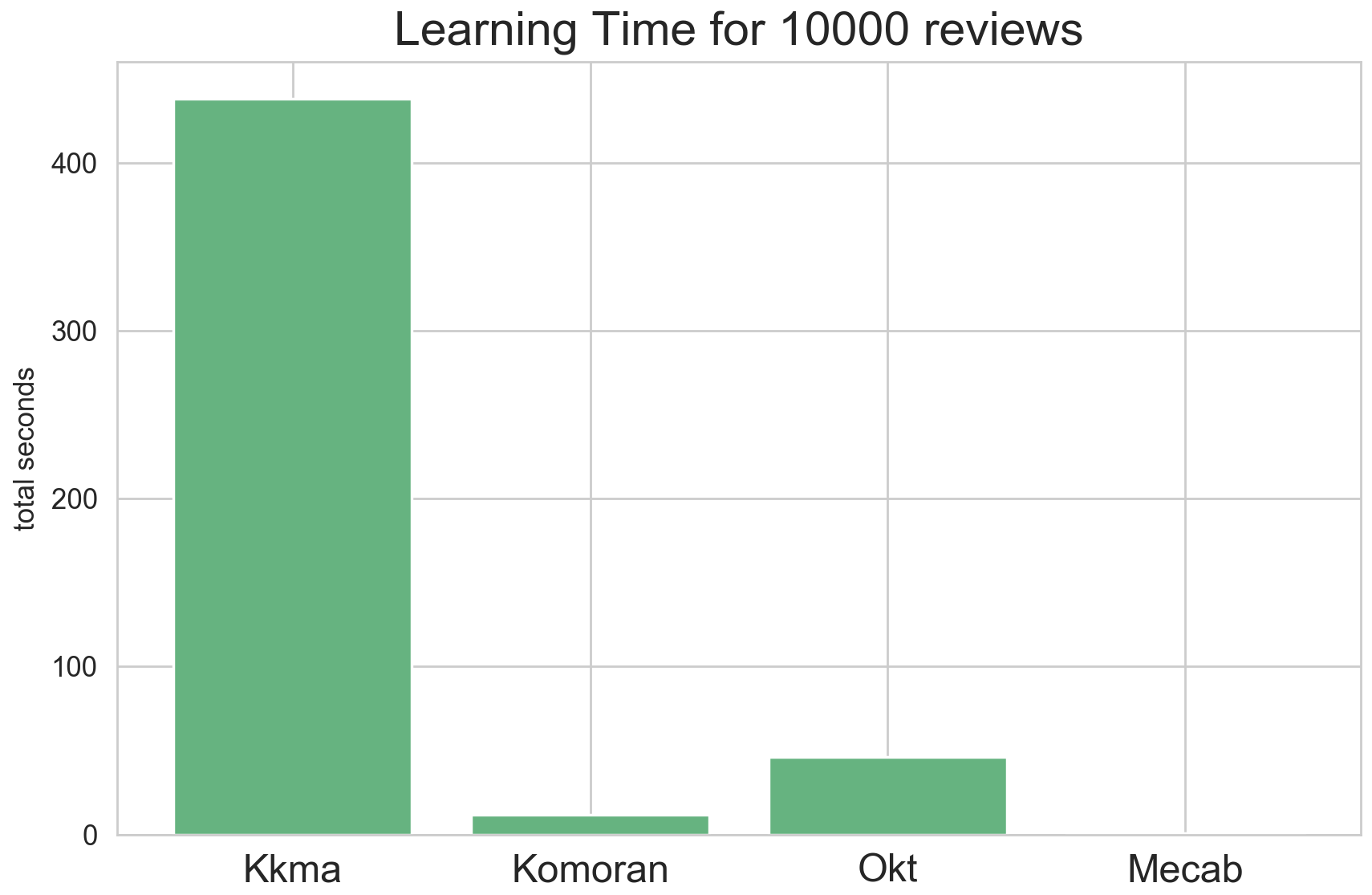
그 결과, Kkma는 약 438초, Komoran은 약 12초, Okt는 약 46초, Mecab은 약 1초 가량의 시간이 소요되었습니다. 속도 면에서는 Kkma가 독보적으로 느리고, Mecab이 독보적으로 빠른 것을 확인할 수 있습니다.
이렇게 각 형태소 분석기를 비교해보고 난 후 개인적인 느낌으로는, 각 형태소 분석기 모두 장단점이 있고, 그 장단점이 서로 다르다는 것입니다. 따라서, 하나만 쓰기보다 서로의 한계를 보완할 수 있도록 몇개를 어떻게 짬뽕해서 쓰는 방안이 없을까 고민하게 되었습니다. 아무튼 대체적으로는, 속도가 중요한 경우에는 Mecab을 쓰는 것이 유리하고, 정규화 기능을 선호한다면 Okt를 이용하는 것이 좋을 것으로 판단됩니다!
){kind=link}