Embedding Projector로 임베딩 벡터 시각화하기
오늘은 Embedding Projector를 이용해서 임베딩 벡터를 시각화해보겠습니다! 준비물은 임베딩하고 난 후의 metadata.tsv와 tensor.tsv 두 데이터가 필요한데요. 이 데이터들은 다음과 같이 얻을 수 있습니다! 먼저 저는 네이버 영화 리뷰를 형태소 분석한 후에, 이 데이터를 다음과 같이 Word2Vec을 훈련시키고 이 모델을 ‘naver_w2v’라는 이름으로 저장했습니다.
from gensim.models import Word2Vec
model = Word2Vec(data, size=100, window=5, min_count=5, workers=4, sg=0)
from gensim.models import KeyedVectors
model.wv.save_word2vec_format('naver_w2v')
이후, 다음과 같이 입력하면, naver_w2v_metadata.tsv와 naver_w2v_tensor.tsv라는 파일이 해당 폴더 내에 저장될 것입니다. 정말 간단하죠?
!python -m gensim.scripts.word2vec2tensor --input naver_w2v --output naver_w2v
이제 Embedding Projector 사이트로 들어가서, 왼쪽에 존재하는 load 버튼을 클릭하면 다음과 같은 창이 나타납니다. 여기서 위에다가 tensor.tsv파일을, 아래에는 metadata.tsv파일을 로드합니다.
먼저 감독이라는 단어를 검색해보았는데요. 다음과 같이 3차원의 구조가 나타나고, 이를 원하는 방향에서 볼 수 있도록 회전시킬 수 있습니다. 유명한 한국 감독들의 이름이 가까이 나타나는 것을 확인할 수 있네요!

한국 배우의 이름을 검색하면 어떨까요? 최민식을 Word2Vec 모델에서 검색하면 다음과 같이 한국 배우들의 이름이 가까이 나타났었는데요.

Embedding Projector로 시각화하면 마찬가지로 다음과 같이 한국 영화배우들의 이름이 가까이 나타나는 것을 볼 수 있습니다. 최민식이라는 배우를 충분히 학습할 만큼 리뷰 데이터에 내용이 많지 않은 것을 감안할 때, 임베딩 결과가 나름 합리적으로 보입니다.

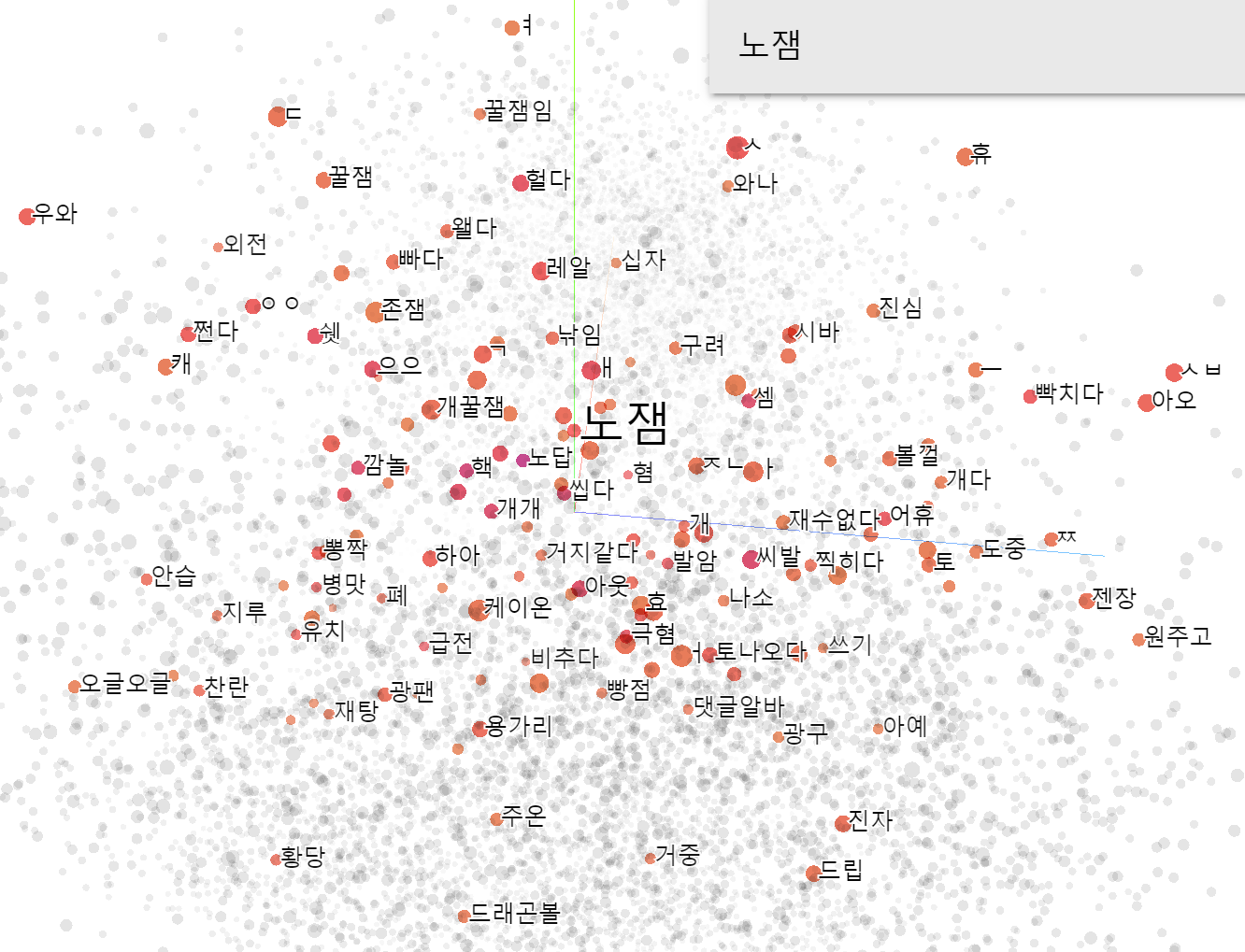
이번에는 노잼을 검색한 결과입니다. 영화에 대한 부정적인 단어들이 가까이 나타나는 것을 볼 수 있습니다. 대표적인 부정적 단어인 만큼, 학습하기도 쉽고 무조건 잘 학습되어야 하는 단어인 것 같습니다.
다음은 대박을 검색한 결과입니다. 대체로 영화에 대한 긍정적인 단어들이 가까이 나타나는 것을 볼 수 있습니다. 이 단어는 리뷰 내용을 긍정으로 분류할 때 큰 역할할 것으로 보입니다.

저는 이 시각화 도구를 처음 접하고 재미있어서 이것저것 많이 검색해보곤 했는데요ㅎㅎ 빠르고 간단하게 임베딩 결과를 한눈에 보고 싶을 때, Embedding Projector를 이용하면 확실히 편리한 것 같습니다!
{kind=link}