네이버 쇼핑 데이터를 이용한 Multi-label Classification (feat. GRU)
Multi-label Classification에 대하여
어떤 상품 리뷰에 대해 대표적으로 할 수 있는 분석은, 리뷰 내용이 긍정적인지 부정적인지 판단(Sentiment Analysis)하는 것이 있을텐데요. 저는 텍스트 분석을 연습하던 중, 감성 분석만 하고 끝나는 것이 아니라, 특히 어떤 부분 때문에 부정적인지, 긍정적인지까지 나아가보고 싶었습니다. 즉, 같은 부정적인 리뷰더라도, 상품의 품질이 마음에 안들었는지, 배송 및 포장 상태가 마음에 안들었는지 여러가지 원인이 있을겁니다. 이렇게 요소를 파악하는 문제와 관련하여, 문장에서 주요 요소를 추출(Aspect Extraction)하는 비지도 학습 방법도 존재하였지만, 깔끔하지 않은 실제 고객 리뷰 데이터에서 비지도 학습을 통해 괜찮은 성능을 당장 얻기에는 어려울 것으로 판단했습니다. 그래서, 리뷰 내용들을 참고하여, 4가지 항목(품질 및 성능, 가격 및 혜택, 배송 및 서비스, 디자인 및 외관)으로 항목 범주를 분류하여, 지도 학습 방법을 이용하고자 했습니다. 즉, 한 리뷰 내용으로부터, 감정(긍정/부정)과 그 감정과 관련한 요소를 동시에 분류(Multi-output Classification)하고자 하였습니다.
자, 그런데 여기서 생각해볼 점은, 한 리뷰가 무조건 하나의 요소만 언급하고 있을까요? 항상 그렇지는 않을겁니다. 예를 들어 다음의 문장은,
튼튼하니 좋네요.
4가지 요소 중 품질 및 성능만을 언급하고 있다고 볼 수 있습니다. 그런데, 다음의 문장이라면,
가격도 저렴하고 튼튼하고 좋아요.
품질 및 성능 뿐만 아니라, 가격 및 혜택도 언급하고 있습니다. 즉, 리뷰마다, 언급하고 있는 요소 개수가 다른 상황입니다. 그렇기 때문에, 4가지 요소 중 한가지로 분류하는 기본 Multi-class 분류와는 다른 접근이 필요할텐데요. 바로, 요소들 각각을 모두 target으로 하는 Multi-label Classification입니다! 4년 전 캐글에서 열린 악성 댓글 분류 대회가 Multi-label 분류 대회였는데요. 특정 악성 댓글에 대해 외설적인 내용이 포함되면 1 아니면 0, 욕설이 포함되면 1 아니면 0 등, 분류해야 할 타겟이 복수인 대회였습니다. 즉, 4가지 요소 각각에 대해, 해당 내용이 포함되었으면 1, 아니면 0으로 Multi-label 분류하고자 합니다. 말로 설명하느라 길어졌는데, 아래에서 데이터로 보면 바로 이해되실거에요! 본격적으로 분석 시작합니다!
데이터 구축 및 전처리
데이터로는, 긍정/부정 라벨링이 되어 있는 네이버 쇼핑 고객 리뷰 데이터를 이용했습니다.

이제 추가적으로 4가지 항목(품질 및 성능, 가격 및 혜택, 배송 및 서비스, 디자인 및 외관)에 대해 라벨링을 직접 진행해야했습니다. 20만 개에 해당하는 모든 리뷰 내용을 직접 수기로 라벨링하기에는 시간이 부족했기 때문에, 다음의 과정들을 통해 효율적으로 라벨링을 진행하고자 했습니다. 먼저 띄어쓰기 및 토큰화 등의 전처리를 진행한 후, 주요 키워드 포함 여부로 1차 라벨링을 진행했습니다. 이후 항목들 각각 하나씩만 라벨링된 리뷰들로 간단한 모델링을 통해 2차 라벨링을 진행했고, 최종적으로 대략적으로 검토하는 시간을 가진 후 데이터 구축을 완료했습니다. 아무래도, 수기로 라벨링하는 것에 비해 정확도가 떨어진다는 한계가 있었습니다ㅠㅠ
즉, 분류해야 할 label 개수는 총 5가지가 됩니다!
- sentiment: 긍정(1), 부정(0)
- quality/performance: 품질 및 성능에 대한 내용 포함(1), 비포함(0)
- price/event: 가격 및 혜택에 대한 내용 포함(1), 비포함(0)
- delivery/service: 배송 및 서비스에 대한 내용 포함(1), 비포함(0)
- design/appearance: 디자인 및 외관에 대한 내용 포함(1), 비포함(0)
전처리
이제 전처리 과정입니다. 전처리 과정은, 딥러닝을 이용한 자연어 처리 입문을 많이 참고하였습니다🙏 우선, 리뷰 내용에 대해, 정규 표현식 수행 및 비어 있거나 중복된 행을 제거합니다.
df['text'] = df['text'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","") #정규 표현식 수행
df['text'].replace('', np.nan, inplace=True) #비어 있는 행은 null값으로 처리
df.dropna(how='any', inplace=True) #null 값 제거
df.drop_duplicates(subset = ['text'], inplace=True) #중복된 행 제거
이제 텍스트를 토큰화해야 하는데요. 토큰화 패키지로는, customized KoNLPy를 이용했습니다. Customized KoNLPy에서는, 일부 토큰들을 직접 지정할 수 있는 기능이 존재하는데, 이는 빈번하게 사용되는 유행어 등을 지정할 때 주로 사용됩니다. 예를 들어, ‘가성비’라는 단어는 ‘가격 대비 성능’을 의미하는데, 쇼핑 리뷰에서 빈번하게 등장하는 단어입니다. 하지만, 일반 KoNLPy 품사 태깅으로 토큰화 진행할 경우, ‘가성비’를 ‘가’, ‘성비’로 분리하는 모습을 보였습니다. 이와 같이, 쇼핑 리뷰에서 빈번하게 등장하는 유행어(?)지만, 잘 못 토큰화될 가능성이 높은 일부 단어들을, customized KoNLPy를 통해 토큰으로 직접 지정해주었습니다.
from ckonlpy.tag import Twitter
twi = Twitter()
words = [('강추','Noun'), ('비추','Noun'), ('가성비','Noun'),
('재구매','Noun'), ('엉성', 'Noun'), ('핏', 'Noun'), ('타이트','Noun')]
for word in words:
name, poomsa = word
twi.add_dictionary(name, poomsa)
이후, 리뷰들에 대해 토큰화를 진행합니다. 아래부터 진행되는 코드에 대한 설명은 딥러닝을 이용한 자연어 처리 입문에 자세히 나와있기 때문에, 설명은 생략하겠습니다!
stopwords = ['의', '가', '이', '은', '들', '는', '과', '도', '를', '으로', '에',
'하다', '을', '이다', '것', '로', '에서', '그', '인', '서', '네요',
'임', '랑', '게', '요', '에게', '엔']
text_token = []
for sentence in df['text']:
tmp = []
tmp = twi.morphs(sentence, stem=True, norm=True) #토큰화
tmp = [word for word in tmp if not word in stopwords] #불용어 제거
text_token.append(tmp)
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(text_token)
threshold = 3
total_cnt = len(tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
단어 집합(vocabulary)의 크기 : 44152
등장 빈도가 2번 이하인 희귀 단어의 수: 26822
단어 집합에서 희귀 단어의 비율: 60.74922993295887
전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 1.2691737130692322
# 빈도수 3이하인 단어 제거하고 0 추가한 개수 = vocab_size
vocab_size = total_cnt - rare_cnt + 1
print('단어 집합의 크기 :',vocab_size)
단어 집합의 크기 : 17331
전체에서 등장 빈도 수가 3 이하인 단어들은 제외하여, (0을 포함한) 전체 단어 집합(vocab_size)의 크기는 17331개로 합니다. 이제 문장을 패딩하기 위해, 문장 길이를 어느정도로 고정할지 정합니다.
tokenizer = Tokenizer(num_words = vocab_size)
tokenizer.fit_on_texts(text_token)
X = tokenizer.texts_to_sequences(text_token)
print('리뷰의 최대 길이 :',max(len(l) for l in X))
print('리뷰의 평균 길이 :',sum(map(len, X))/len(X))
리뷰의 최대 길이 : 58
리뷰의 평균 길이 : 12.36651295354987
def below_threshold_len(max_len, nested_list):
cnt = 0
for s in nested_list:
if(len(s) <= max_len):
cnt = cnt + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))*100))
max_len = 35
below_threshold_len(max_len, X)
전체 샘플 중 길이가 35 이하인 샘플의 비율: 97.29337795864298
문장 길이가 35로 할 경우, 약 97%의 대부분의 샘플을 커버 가능합니다. 문장 길이(max_len)는 35로 결정합니다. 이제, 각 리뷰 샘플들에 대해 패딩을 진행합니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(X, maxlen = max_len)
X
array([[ 0, 0, 0, ..., 11842, 25, 273],
[ 0, 0, 0, ..., 155, 1599, 1868],
[ 0, 0, 0, ..., 5, 169, 245],
...,
[ 0, 0, 0, ..., 101, 372, 421],
[ 0, 0, 0, ..., 1688, 17, 323],
[ 0, 0, 0, ..., 76, 3, 205]])
한편, target에 해당하는 y에는 5개의 label(sentiment, quality/performance, price/event, delivery/service, design/appearance)이 들어가게 됩니다.
y = np.array(df.iloc[:,:5])
y
array([[1, 0, 0, 1, 0],
[0, 0, 0, 1, 0],
[1, 1, 1, 0, 0],
...,
[1, 0, 1, 0, 0],
[1, 0, 0, 0, 1],
[1, 0, 0, 1, 0]], dtype=int64)
자, 이로써 학습에 이용할 X, target인 y를 모두 구축했고, 모델링을 위해 train, test set 분리를 합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
X_train = np.array(X_train)
X_test = np.array(X_test)
모델링
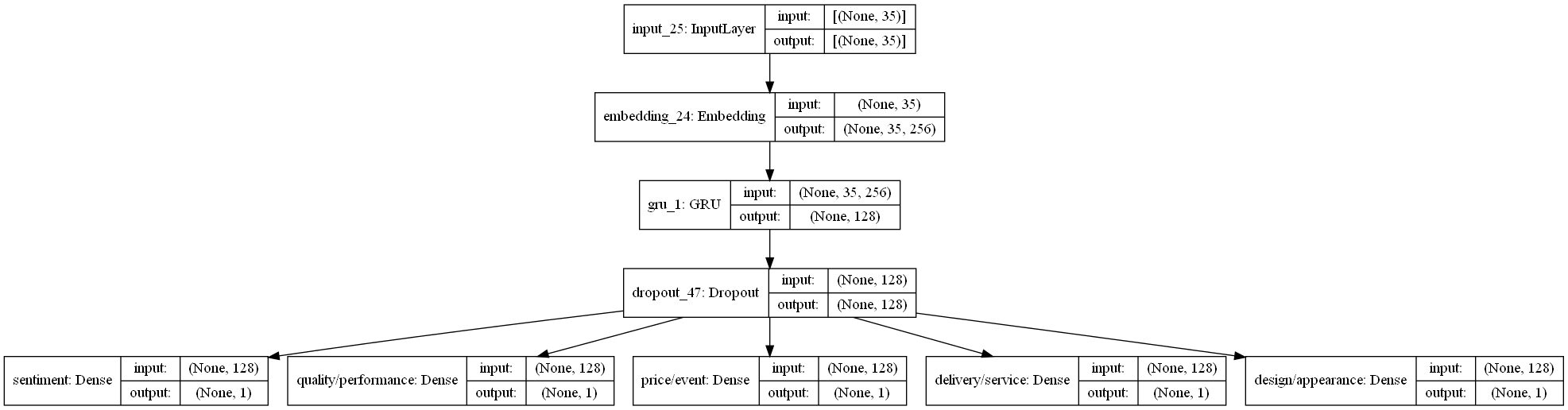
데이터 구축과 전처리를 모두 완료했고, 모델링을 진행할 차례입니다! 아래 그림과 같이 GRU를 이용한 Multi-label 아키텍처를 이용하여 모델링을 진행하고자 합니다. 즉, 각 5개의 이항 분류를 동시에 진행하는, Multi-output Binary Classification 문제입니다.
각각의 이항 분류에 있어, 지표는 F1-score로 결정했습니다. 대체로, 품질 및 성능에 대한 언급은 상당 수가 포함하고 있는 것에 비해, 가격 등의 그 외 요소들에 대해서는 비포함 비율이 훨씬 높아, 비율 차이가 불균형했기 때문입니다.
import tensorflow.keras.backend as K
def F1score(y_true, y_pred):
eps = K.epsilon()
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
real_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
pred_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
recall = true_positives / (real_positives + eps)
precision = true_positives / (pred_positives + eps)
f1_score = 2 * (recall * precision) / (recall + precision + eps)
return f1_score
본격적으로 fit하기 전에, multi-output 구조에 맞게 다음과 같이 y를 딕셔너리 형태로 변경해줍니다.
label_names = df.columns[:5] #label 종류
n_label = len(label_names)
y_train_list = {label_names[i]:y_train[:,i] for i in range(n_label)}
y_test_list = {label_names[i]:y_test[:,i] for i in range(n_label)}
y_train_list
{'sentiment': array([1, 1, 1, ..., 0, 0, 0], dtype=int64),
'quality/performance': array([0, 1, 0, ..., 1, 1, 1], dtype=int64),
'price/event': array([0, 0, 0, ..., 0, 0, 0], dtype=int64),
'delivery/service': array([0, 0, 1, ..., 0, 0, 0], dtype=int64),
'design/appearance': array([1, 1, 0, ..., 0, 0, 0], dtype=int64)}
이제 모델 식을 세워줍니다!
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.layers import Input, Embedding, Dense, GRU, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
def SimpleGRU():
input_layer = Input(shape=(max_len,))
embedding_text = Embedding(vocab_size, 256)(input_layer)
x = GRU(128)(embedding_text)
x = Dropout(0.5)(x)
output_layers = [Dense(1, activation="sigmoid", name=label_names[i])(x) for i in range(y.shape[1])]
model = Model(inputs=input_layer, outputs=output_layers)
model.compile(loss=['binary_crossentropy']*n_label, optimizer='rmsprop', metrics=[F1score])
return model
model = SimpleGRU()
callback_list = [EarlyStopping(monitor='val_loss', patience=4),
ModelCheckpoint(filepath='best_model.h5', monitor='val_loss', save_best_only=True)]
history = model.fit(X_train, y_train_list, epochs=20, batch_size=60, validation_split=0.1, callbacks=callback_list)
에폭에 따른 각 label들의 성능 값을 시각화해보겠습니다.
def history_to_value(history, n_label):
history_out = pd.DataFrame(history.history)
epochs = history_out.shape[0]
history_out = history_out.drop('loss', axis=1).stack().reset_index()
history_out['F1score'] = history_out['level_1'].apply(lambda x: 1 if x.split('_')[-1] =='F1score' else 0)
history_out['label_kind'] = history_out['level_1'].apply(lambda x: x.split('_')[-2])
history_out['data'] = history_out['level_1'].apply(lambda x: 'validation' if len(x.split('_')) == 3 else 'train')
history_out = history_out[history_out['F1score'] == 1][[0, 'label_kind', 'data']].rename(columns={0:'values'}).reset_index(drop=True)
history_out.sort_values(by=['label_kind', 'data'], inplace=True)
history_out['epochs'] = list(range(1,epochs+1)) * n_label * 2
return history_out
def plotDF(history, n_label):
history_out = history_to_value(history, n_label)
fig = sns.relplot(data=history_out, x="epochs", y="values", hue="data", col="label_kind", linewidth=2.5, kind='line', col_wrap=3,
marker='o', palette=pal[:2], height=3, aspect=0.8)
plt.legend(loc='lower right')
leg = fig._legend
leg.set_bbox_to_anchor([0.9,0.3])
fig.set(ylim=(0.6, 1), ylabel='F1 score')
plotDF(history1, n_label)
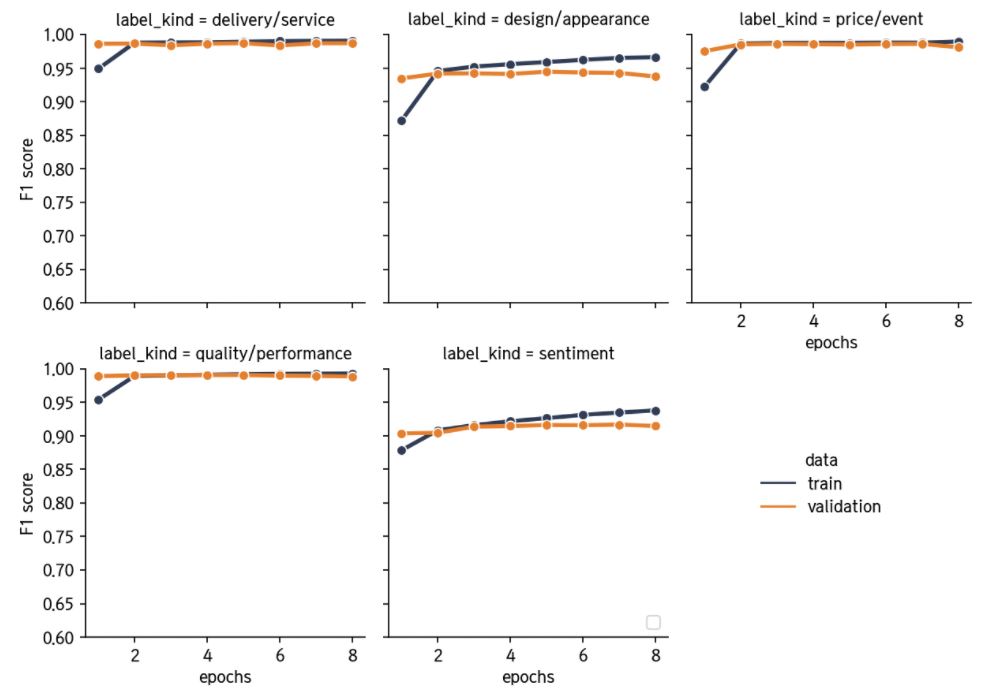
학습 과정에서 저장한 best_model로 test set에서의 결과도 확인합니다.
best_model = load_model('best_model.h5', custom_objects = {'F1score':F1score})
best_model.evaluate(X_test, y_test_list, batch_size=60)
665/665 [==============================] - 5s 7ms/step - loss: 0.4103 - sentiment_loss: 0.2328 - quality/performance_loss: 0.0550 - price/event_loss: 0.0165 - delivery/service_loss: 0.0264 - design/appearance_loss: 0.0797 - sentiment_sentiment_F1score: 0.9115 - quality/performance_quality/performance_F1score: 0.9903 - price/event_price/event_F1score: 0.9874 - delivery/service_delivery/service_F1score: 0.9886 - design/appearance_design/appearance_F1score: 0.9455
[0.4102814495563507,
0.23277169466018677,
0.05498204380273819,
0.016451003029942513,
0.026363756507635117,
0.07971274852752686,
0.9114562273025513,
0.9903451800346375,
0.987377405166626,
0.9885985255241394,
0.9454994797706604]
Sentiment, Category 분류 프로그램
여기까지 간단 모델링을 모두 완료했습니다! 이번에는, 특정 리뷰를 인풋으로 집어넣었을 때, 앞서 얻은 best_model의 분류 결과를 시각화해서 알려주는 프로그램을 만들어보고자 합니다.
def predict_review(sentence, max_len=35):
#Preprocess, Predict
sentence = sentence.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","") # 정규 표현식 수행
if sentence == '':
return "리뷰 해석 불가."
new = twi.morphs(sentence)
new = [word for word in new if not word in stopwords]
encoded = list(filter(lambda x: x>0, [tokenizer.word_index.get(i,0) for i in new])) #단어를 인덱스로 바꿈
pad_new = [0]*(max_len-len(encoded)) + encoded # 패딩
scores = [i[0][0] for i in best_model.predict(np.array([pad_new]))] #이전에 학습한 모델로 예측한 후 결과 저장.
#Visualize
fig, ax = plt.subplots(1,2, figsize=(9,4))
x, y = label_names[:0:-1], scores[:0:-1]
colors = ['#E47F2D' if yy > 0.5 else '#747B86' for yy in y] ##확률이 0.5 넘는 경우 주황색
ax[0].barh(x, y, color=colors, height=0.5)
ax[0].set_title("Category")
ax[0].set_xlim(0,1)
for i in range(4):
ax[0].text(y[i]+0.01, x[i], '{:.2f}%'.format(y[i]*100), verticalalignment='center')
simpleaxis(ax[0])
x, y = ["긍정", "부정"], [scores[0], 1-scores[0]]
colors = ['#E47F2D' if yy > 0.5 else '#747B86' for yy in y]
ax[1].bar(x, y, width=0.25, color=colors)
ax[1].set_title("Sentiment")
ax[1].set_ylim(0,1)
for i in range(2):
ax[1].text(x[i], y[i]+0.03, '{:.2f}%'.format(y[i]*100), horizontalalignment='center')
simpleaxis(ax[1])
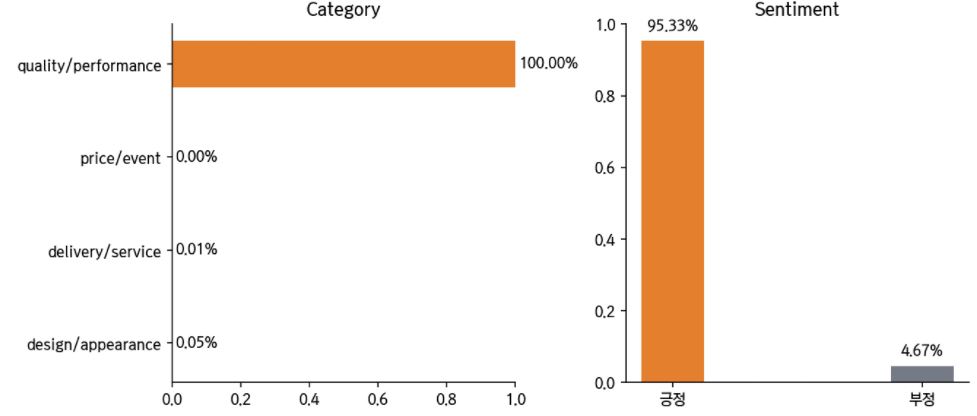
이제 문장을 집어 넣고 분류 결과를 살펴보겠습니다. “퀄리티 괜찮아요”와 “퀄리티 대박 좋아요” 두 문장이 있을 때, 후자의 경우 긍정일 확률이 매우 높아진 것을 볼 수가 있네요!
text = "퀄리티 괜찮아요"
predict_review(text)
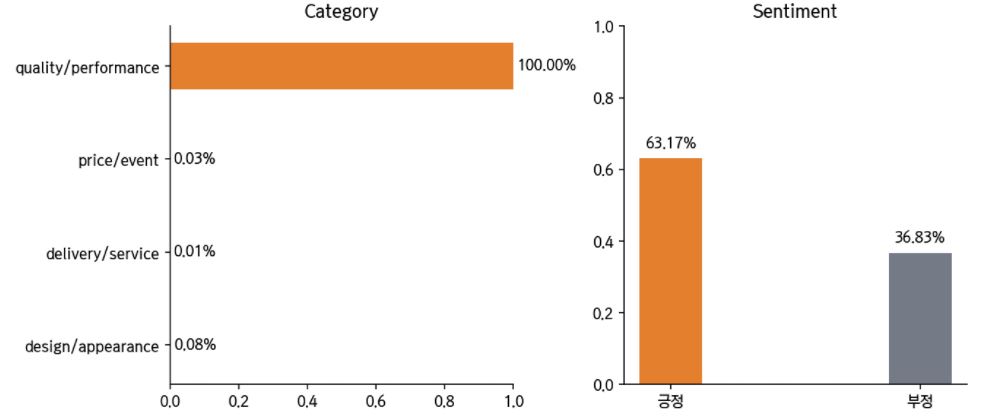
text = "퀄리티 대박 좋아요"
predict_review(text)
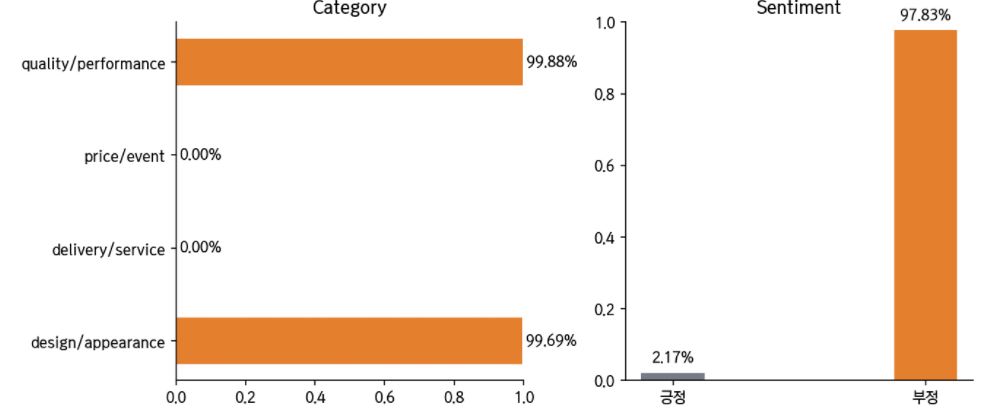
리뷰 내용에 언급된 카테고리가 2개 이상일 때에도, 다음과 같이 확인할 수 있습니다.
text = "제품 실밥도 많이 풀려있고 허접합니다 크기도 대형인가 싶을 정도로 크진 않네요"
predict_review(text)
한계점
이렇게 해서 Multi-label Classification을 진행해보았습니다! 하지만, 일부 한계점들이 있는데요.
-
데이터 라벨링의 정확도 부족
수기로 직접 라벨링한 것이 아니기에, 라벨링 정확도가 현저히 부족하였습니다. 하지만, 이는 정확하게 라벨링이 되어 있는 다른 데이터가 존재할 경우 문제가 되는 부분은 아닙니다. -
Label 간 상호 의존성 무시
해당 포스트에서는, 4가지 항목(품질, 가격, 배송, 디자인) 각각에 대해 독립적으로 이항 분류를 진행했는데요. 이렇게 하는 것은, 각 4가지 label이 서로 독립적 관계라는 전제를 깔고 가게 됩니다. 상품 또는 쇼핑 경험에 대한 여러가지 카테고리들이 완전히 상호 독립적 관계라고 보기 어렵기 때문에, 이들의 관계를 무시하고 각각 이항 분류를 하는 것은 엄밀하게는 허점이 존재합니다. Deep dive into multi-label classification..! (With detailed Case Study)를 참고하면, 모든 분류 조합에 대해 학습시키는 방법, 또는 이전 label에 대한 분류기 예측값을 그 다음 label 분류에 변수로서 사용하는 방법인 Classifier Chains 등 Multi-label 문제를 푸는 여러가지 방법이 있는 것을 확인할 수 있었습니다. 따라서, 이들의 의존 관계를 반영할 수 있는 다른 방법을 시도할 필요성이 있습니다.
Reference
- 딥러닝을 이용한 자연어 처리 입문
- customized KoNLPy
- Deep dive into multi-label classification..! (With detailed Case Study)
){kind=link}