[기초통계학] 1편. 통계학의 개요와 추정(+신뢰구간 등)에 대한 직관 이해
안녕하세요! 두 편에 걸쳐 기초통계학에 대해 포스팅을 진행하려고 합니다:) 목표는 기초 통계학에 대한 직관을 이해하는 것이구요. 통계학에서 다루는 여러가지 분석 방법론들을 다룰 때 매번 나오게 될 개념들에 대해 먼저 한번 브리핑하고자 합니다. 신뢰구간의 의미가 무엇인지, 유의성 검정이란 무엇인지, 가설 검정에서 왜 유의수준보다 p-value가 작으면 기각하는지 등등 통계학에 대한 기초 개념을 크게 한번 이해해보도록 하겠습니다👊 이번 포스트에서는 먼저 통계학의 개요와 추론 통계학의 한 갈래인 추정(Estimation)을 살펴보겠습니다.
통계학의 개요
어떤 연구자가 (통계적인) 연구를 할 때, 많은 경우 아래의 4가지 단계로 그 과정이 요약이 될 수 있을 것입니다.
-
1단계: 자료 수집
-
2단계: 자료 정리 및 탐색
-
3단계: 통계 분석
-
4단계: 분석 결과 해석 및 결론 내리기
1단계에서는 자신의 연구 주제와 관련하여 연구 대상이 되는 자료를 수집합니다. 2단계에서는 그 자료를 정리하고, 요약하며, 그래프로도 나타내면서 자료에서 나타나는 전반적인 특징을 파악합니다. 3단계에서는 자신의 연구 주제 및 가설을 가지고 통계적으로 분석을 진행합니다. 마지막 4단계에서는 분석 결과를 해석하고, 자신의 연구 주제에 대한 결론을 내리게 됩니다. 그런데 이 모든 절차가 통계학에서 다루는 내용이라는 겁니다!
먼저, 첫 두 단계에서 하는 내용은 통계학에서 기술통계학(Descriptive Statistics) 으로 일컬어지는 분야입니다. 수집된 자료를 그래프 및 표 등을 통해 분포를 파악하거나, 평균, 분산 등의 몇개의 수치로 요약, 묘사하는 분야입니다. 한편, 세,네번째 단계에서 하는 내용은 통계학에서 추론통계학(Inferential Statistics) 또는 통계적 추론(Statistical Inference)으로 일컬어지는 분야입니다. 이 분야에서는, 주어진 자료에 대한 통계적 분석을 통해, 자신의 가설에 대한 결론을 내리거나 경우에 따라서는 미래 예측을 하기도 하는데요. 아마 많은 사람들에게 바로 이 분야, 통계적 추론이, 통계학을 공부하는 주요 목적이 될것입니다! 그렇다면, 이제부터 통계적 추론이라는 과정에 대해 더욱 살펴보도록 하겠습니다.
통계적 추론
통계적 추론이란, 자료에서 얻은 경험적 사실을 바탕으로, 그 자료가 얻어진 모집단에 관한 어떤 결론을 이끌어내는 과정입니다. 다들 잘 아시겠지만 보통 저희에게 주어진 자료는 관심 대상의 극히 일부분(표본)에 불과하고, 저희의 궁극적인 관심 대상(모집단)에 대한 찐 자료는 거의 얻을 수가 없을 겁니다. 예를 들어, “00법안에 대한 우리나라 사람들의 선호도”를 알고 싶을 때, 우리나라의 투표권 있는 모든 사람들에게 한명 한명 의견을 물어볼 수는 없으니까, 딱 적당한 수의 우리나라 성인을 골고루 추출해서, 이 사람들의 의견을 우리나라 전체 성인의 의견으로 유추를 하는 것이죠.
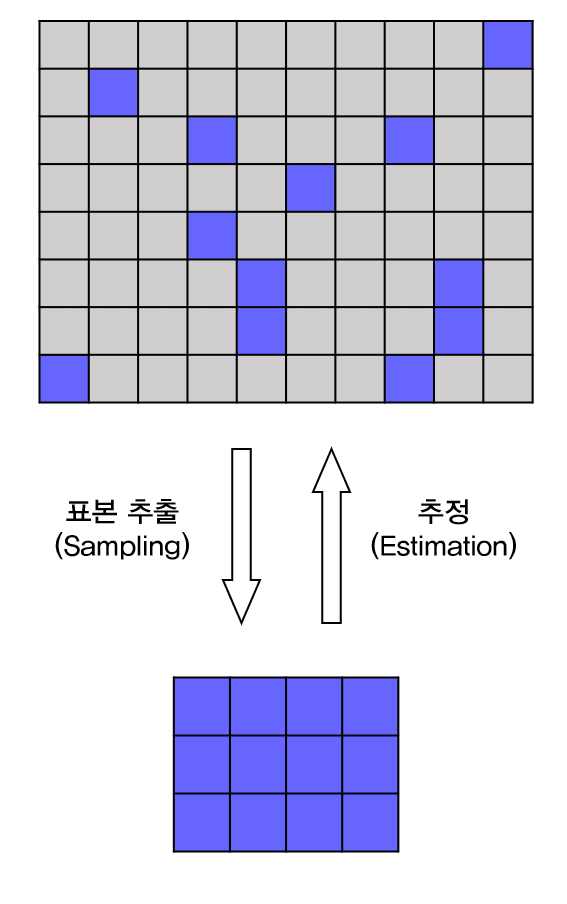 통계적 추론
통계적 추론
00법안에 대한 선호도를 파악한다고 할 때, 아래와 같이 구체적으로 써보겠습니다.
우리나라 성인의 00법안에 대한 찬성 비율을 파악하기 위해, 우리나라 성인 1000명을 추출하여 이들의 00법안에 대한 찬성 비율을 조사했다.
여기서 우리나라 성인이 모집단(Population)이 되고, 00법안에 대한 찬성 비율이 모수(Parameter), 즉 모집단에 대한 관심 있는 값을 의미합니다. 그리고, 우리나라 성인 1000명이 표본(Sample)이고, 이들의 00법안에 대한 찬성 비율이 통계량으로, 표본에 대하여 계산한 값을 의미합니다.
그런데, 내가 가진 데이터를 가지고 추론을 했다고 했을 때, 그 결과를 완전히 믿을 수 있을까요? 우리나라 성인 1000명을 추출해서 00법안에 대한 찬성 비율을 얻었다고 해서, 우리나라 성인의 찬성 비율이 실제로 이렇다고 장담할 수는 없을 겁니다. 1000명이면 그래도 꽤 많은 숫자지만, 표본이 500명, 100명, 50명 이렇게 줄었다고 하면, 그 결론에 대해 어느정도 믿을 수 있을지도 관건이 되겠죠! 결국, 표본은 일부분에 불과하기 때문에, 표본을 가지고 추론하는 과정은 무조건 불확실성을 수반하게 될 것입니다. 이 때, 내가 제시한 근거가 어느 정도의 신뢰도를 가지는지를 정량적으로 함께 제시를 해주어야, 과학적인 결론이라고 할 수 있을 것입니다. 즉, 통계적 추론 과정에서는, “이렇게 분석 결과가 나와서 결론 냈어요! 끝!”이 아니라, “이렇게 분석 결과가 나왔고, 이는 00 정도 믿을 수 있어요!”라고 끝맺음을 내주어야 합니다.
이와 관련하여, 통계적 추론의 주요 두가지 과제를 이제 소개하겠습니다. 바로 추정(Estimation)과 검정(Testing)입니다! 추정은, “표본을 가지고 모수를 추정하고, 그 추정된 값을 어느정도 신뢰할 수 있을지 파악하는 과정”입니다. 검정은, “모수(또는 모분포)에 대한 어떤 주장이 표본에 의해 얼마나 지지되는지 평가함으로써, 주장의 진위여부를 판단하는 과정”입니다. 이번 포스트에서는 먼저 추정에 대해서 살펴보려고 합니다.
추정
-
우리나라 여성의 평균 키
-
우리나라 성인의 흡연 비율
위와 같이 특정 미지의 수에 대한 추론을 하는 것을 추정이라고 합니다. 특히 이렇게 하나의 값을 추정한다는 의미에서 점 추정(point estimation)이라고 합니다. 이렇게 구한 하나의 점 추정치는, 주어진 표본에 대한 통계량입니다. 그런데, 표본이 바뀌면 이 통계량 값이 어떻게 될까요? 매 표본마다 같은 추정치 값이 나오지는 않겠죠. 하필 한번 얻었던 그 때의 표본이 유난히 튀는 값들이 많아서 통계량 값도 극단적으로 나오게 되면 대참사가 되겠죠ㅠㅠ 그렇기 때문에 보통 하나의 점 추정치만 제시하기 보다는, 오차를 부여해서 신뢰할 수 있는 구간을 함께 제시를 하게 됩니다. “이 정도 오차 범위 내에 참값이 있을거고, 이에 대해 00% 확신한다”는 정보인데, 이게 바로 신뢰구간을 의미합니다!
신뢰구간
표본을 수천번 반복해서 얻은 점추정치들의 분포를 구해서, 이 분포의 95%를 아우르는 구간을 95% 신뢰구간이라고 합니다. 이 분포를 표본을 통해 얻은 분포라는 의미에서, 표본 분포(Sampling Distribution)라고 합니다. 표본을 10,000번 추출해서 얻은 10,000개의 00법안에 대한 찬성 비율들이 $0.48 \pm 0.03$ 구간 이내에 집중적으로 분포가 되어있다고 해보겠습니다. 아래 그림처럼 10,000개 중 95%가 포함되는 이 구간 $[0.45, 0.51]$ 이 95% 신뢰구간이 됩니다. 그리고, 통계학에서는 표본평균들의 평균이 모평균과 같아진다는 수학적인 증명 결과가 있습니다! (시뮬레이션을 통해서도 확인할 수 있습니다.) 따라서, 95%의 표본 비율들은 참값을 중심으로 오차범위 $\pm 0.03$ 이내에 있다고 할 수 있겠네요.
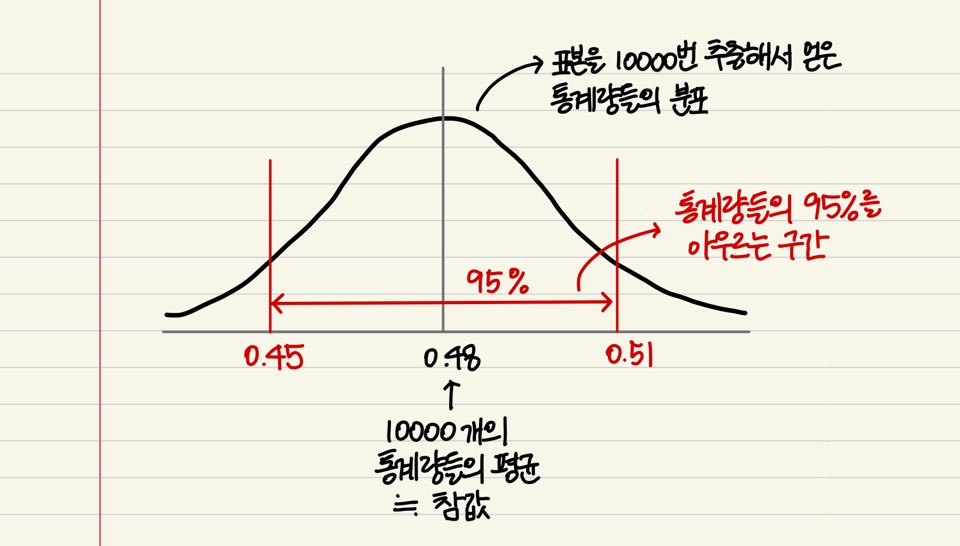 신뢰구간의 의미
신뢰구간의 의미
한편, 95% 신뢰구간을 해석하는데 있어서 유의해야 할 점은, 참값이 $[0.45, 0.51]$ 구간 내에 있을 확률이 95%라고 해석하는 게 아니라는 겁니다. 이보다는 표본을 뽑아 얻은 구간들의 95% 정도가 참값을 포함한다고 해석해야 합니다!
그나저나 신뢰구간의 의미는 이제 알겠는데 그렇다고 해서 매번 추출을 수만번, 수천번씩 뽑아서, 표본 분포를 이렇게 직접 얻기는 현실적으로 쉽지 않을 겁니다😂 다행히도, 이론적인 정리에 의해 표본 분포를 쉽게 구할 수가 있습니다. 여기서 등장할, 그 유명한 정리를 아시나요? 네, 바로 중심극한정리(Central Limit Theorem)입니다. 중심극한정리는, 표본 크기가 충분히 크면 표본평균들의 분포가 정규분포에 근사한다는 겁니다. (중심극한정리에 대한 설명은 이곳을 참고하시면 됩니다.) $n$개의 표본에서 얻은 표본 평균 $\bar X_n$가 정규분포에 근사하는 것을 이용해서, 95% 신뢰구간을 추정할 수 있게 됩니다.
표본 분포: $\bar X_n \sim \space N(\mu,\sigma^2/n) \quad by\space CLT$
95% 신뢰구간 추정: $[\bar X_n - z_{\alpha/2}\frac{\sigma^2}{n},\space \bar X_n + z_{\alpha/2}\frac{\sigma^2}{n}]$
자, 여기까지 통계학의 개요와 통계적 추론의 첫 과제 추정에 대해 알아보았습니다! 다음 포스트에서는 두번째 과제인 검정에 대해 알아보도록 하겠습니다:) 감사합니다.
$Reference$
- 통계적 탐구, 김기영$\cdot$박유성$\cdot$송석헌$\cdot$이재원$\cdot$장인식$\cdot$전명식$\cdot$허명회, 교우사, 2002
%EC%97%90%20%EB%8C%80%ED%95%9C%20%EC%A7%81%EA%B4%80%20%EC%9D%B4%ED%95%B4){kind=link}